
a couple hundred
US
UK
- Determiner
- Approximately two hundred.
- Phrase
- A small number of hundreds; more than one hundred but not many.
A2Moreapplication
US /ˌæplɪˈkeʃən/
UK /ˌæplɪˈkeɪʃn/
- Noun (Countable/Uncountable)
- Software program, e.g. for smart phone
- Process of spreading a substance over a surface
A2TOEICMoreas time goes by
US /əz taɪm ɡoʊz baɪ/
UK /əz taɪm gəuz baɪ/
- other
- Over the course of time; as time passes.
B2Moreas useful
US
UK
- Phrase
- Equally useful; to the same degree of usefulness.
as well as
US /æz wɛl æz/
UK /æz wel æz/
- Adverb
- Also; in addition to
- Preposition
- In addition to; and also.
A1Moreat a time
US /æt e taɪm/
UK /æt ə taim/
- Phrase
- Separately; one by one
- Simultaneously; together
A1Morebad idea
US
UK
- Phrase
- An unwise or imprudent course of action.
A2Morebased on
US
UK
- Phrasal Verb
- To use something as the foundation or starting point for something else.
- Preposition
- Using something as the main idea or foundation.
- Relying on something as evidence or justification.
A1Morebuffer
US /ˈbʌfɚ/
UK /ˈbʌfə(r)/
- Noun (Countable/Uncountable)
- Data in computer memory allowing fast access
- Protection to prevent things mixing
- Transitive Verb
- To store data in special memory for fast access
- To protect a thing by separating it from
B2Morebump up
US /bʌmp ʌp/
UK /bʌmp ʌp/
- Phrasal Verb
- To increase something, often by a small amount.
- To promote someone to a higher position.
B2Moreby default
US /baɪ dɪˈfɔlt/
UK /bai diˈfɔ:lt/
- Adverb
- Automatically, unless the user specifies otherwise.
- Because of a lack of any other action or choice.
by definition
US /baɪ ˌdɛfəˈnɪʃən/
UK /bai ˌdefiˈniʃən/
- Phrase
- Inherently; as an essential quality or characteristic.
B2Morecompete in
US
UK
- Phrasal Verb
- To take part in a contest or competition.
B1Moredepending on
US
UK
- Phrasal Verb
- To rely on for support (financial or emotional)
- Influenced or determined by.
- Preposition
- Subject to; contingent on
- Relying on someone or something for support or assistance.
A2Moreend in
US /ɛnd ɪn/
UK /end in/
- Phrasal Verb
- To have something as the final result.
figure out
US /ˈfɪɡjɚ aʊt/
UK /ˈfiɡə aut/
- Phrasal Verb
- To understand the behavior of someone
- To think through logically to find a solution
- Verb (Transitive/Intransitive)
- To understand or find an answer to something.
- To find a solution to a problem or understand something.
A1Morefit into
US /fɪt ˈɪntu/
UK /fit ˈɪntuː/
- Phrasal Verb
- To be small enough to go inside something.
- To feel like you belong to a group.
A2Morefor instance
US /fɔr ˈɪnstəns/
UK /fɔ: ˈinstəns/
- Adverb
- As an example.
- Phrase
- As an example.
- As an illustration or case in point
B1Morefor the heck of it
US /fɚ ðə hɛk əv ɪt/
UK /fə ðə hek əv ɪt/
- other
- Doing something without serious reason, just out of curiosity or fun.
B2Morefor the most part
US
UK
- Phrase
- Generally; mostly; on the whole.
- Mostly; generally; in most cases.
A1Moreforget about
US /fɚˈɡɛt əˈbaʊt/
UK /fəˈɡet əˈbaut/
- Phrasal Verb
- To stop thinking about something; to ignore something.
A1Morego ahead
US /ɡo əˈhɛd/
UK /ɡəu əˈhed/
- Phrasal Verb
- To start an activity; start doing, working etc.
- To give permission to do something
- Intransitive Verb
- To start or proceed with something
- To proceed despite potential obstacles or doubts.
A1Morego into detail
US
UK
- Verb (Transitive/Intransitive)
- To explain or describe something fully and completely.
A1Morego on
US /ɡo ɑn/
UK /ɡəu ɔn/
- Phrasal Verb
- To continue doing something
- To happen (usually negative)
- Interjection
- Used to encourage someone
A1Moregoing on
US /ˈɡoɪŋ ɑn/
UK /ˈgəʊɪŋ ɔn/
- Phrasal Verb
- To continue doing something
- To happen (usually negative)
A1Moregot to
US /ɡɑt tu/
UK /gɔt tu:/
- Verb (Transitive/Intransitive)
- To arrive at some place
- To have the opportunity or permission to do something
- Phrasal Verb
- To appeal to the emotions of; move
- To finally begin to start something after a delay
A1Morehave to
US /hæv tu/
UK /ˈhæv tə/
- Auxiliary Verb
- Must do
A1Morein case of
US /ɪn kes ʌv/
UK /in keis ɔv/
- Preposition
- If something happens; in the event of.
- If something happens.
- Conjunction
- To be prepared for something that might happen.
A1Morein charge
US /ɪn tʃɑrdʒ/
UK /in tʃɑ:dʒ/
- Adverb
- To be responsible for
A1Morein general
US /ɪn ˈdʒɛnərəl/
UK /in ˈdʒenərəl/
- Phrase
- Typically; usually; on the whole.
- Not specific or detailed; broadly.
- Adjective
- Not detailed or specific; overall.
C2Morein on
US
UK
- Phrase
- To be involved in a secret or plan.
- To be aware of something that is secret or not generally known.
A1Morein terms of
US
UK
- Phrase
- With regard to; concerning a particular aspect.
A1Morein the way
US /ɪn ði we/
UK /in ðə wei/
- Phrase
- Obstructing someone or something; hindering progress.
- Stored or placed so as to be available or ready when needed.
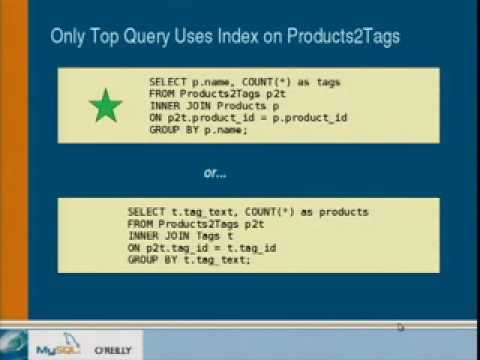
A1Moreindex
US /ˈɪnˌdɛks/
UK /ˈɪndeks/
- Noun (Countable/Uncountable)
- Number showing how prices, wages changed over time
- Written or printed (usually alphabetical) list
- Transitive Verb
- To adjust a value/wages as other things change
- To make a list of things in alphabetical order
A2TOEICMoreindistinct
US /ˌɪndɪˈstɪŋkt/
UK /ˌɪndɪˈstɪŋkt/
- Adjective
- Not clearly defined; not easy to see or hear
B2TOEICMoreinstead of
US /ɪnˈstɛd ʌv/
UK /inˈsted ɔv/
- Preposition
- When one thing is replaced by another
- Adverb
- As a substitute or alternative.
A1Moreinto detail
US /ˈɪntu ˈditel/
UK /ˈɪntəʊ ˈdi:teɪl/
- other
- To explain or discuss something thoroughly with many specifics.
B1Morejoin in
US /dʒɔɪn ɪn/
UK /dʒɔin in/
- Phrasal Verb
A1Morejust kind of
US
UK
- Phrase
- Used to express a feeling or state in a vague or hesitant way.
- Used to indicate something is approximately or generally similar to something else.
A2Morelead to
US /lid tu/
UK /li:d tu:/
- Phrasal Verb
- To result in some action
- Verb (Transitive/Intransitive)
- To have something as a consequence or result.
A1Morelook around
US /lʊk əˈraʊnd/
UK /luk əˈraund/
- Phrasal Verb
- To explore a place; search for something.
A1Morelook at
US /lʊk æt/
UK /luk æt/
- Phrasal Verb
- To use your eyes to focus on something
- To focus your eyes on something carefully
A1Morelook for
US /lʊk fɔr/
UK /luk fɔ:/
- Phrasal Verb
- To try to find a thing or person that is lost
- To expect or anticipate something.
A1Moreon to
US /ɑn tu/
UK /ɔn tu:/
- Preposition
- Toward something; forward
- Aware of someone's activities.
- Adjective
- Aware of someone's deception or illegal activities.
A1Moreout of it
US /aʊt ʌv ɪt/
UK /aut ɔv it/
- Adjective
- Unconscious or not completely alert; dazed or confused.
- Not able to think clearly or react quickly; not with it.
A1Moreover time
US /ˈovɚ taɪm/
UK /ˈəuvə taim/
- Phrase
- Gradually; as time passes.
- During a long period.
- Adverb
- Gradually; as time passes.
B1Moreperformance
US / pɚˈfɔrməns/
UK /pə'fɔ:məns/
- Noun
- Act of doing something
- Activity done to entertain an audience
A2TOEICMoreplay around
US
UK
- Phrasal Verb
- To cheat on your partner romantically
A1Moreprimary
US /ˈpraɪˌmɛri, -məri/
UK /'praɪmərɪ/
- Adjective
- Most important, most basic or essential
- Happening first; earliest
B2Morerather than
US
UK
- Adverb
- More exactly; more correctly
- Preferably; instead
- Preposition
- Instead of
A1Moreregardless of
US /rɪˈɡɑrdlɪs ʌv/
UK /riˈɡɑ:dlis ɔv/
- Phrase
- Preposition
- Without being affected or influenced by something; despite.
A2Moreright back
US /raɪt bæk/
UK /rait bæk/
- Interjection
- Said when someone says they will return soon, indicating you expect their prompt return.
- Adverb
- Immediately; very soon after going.
A1Morerun on
US /rʌn ɑn/
UK /rʌn ɔn/
- Phrasal Verb
- To continue longer than expected, e.g. a meeting
- To talk without stopping, often on the same topic
- Intransitive Verb
- To continue without a break or clear separation, especially in writing.
A1Moreserver
US /ˈsɚvɚ/
UK /'sɜ:və(r)/
- Countable Noun
- A computer which distributes files to others
- Noun (Countable/Uncountable)
- Person who gives food to others at a table
A2Moreset up
US /sɛt ʌp/
UK /set ʌp/
- Phrasal Verb
- To make arrangements for something; establish
- Verb (Transitive/Intransitive)
- To arrange or prepare something for use.
- To start a business, organization, etc.
A1Moreshout out
US /ʃaʊt aʊt/
UK /ʃaut aut/
- Noun
- A public expression of greeting or praise.
- Verb (Transitive/Intransitive)
- To publicly mention or acknowledge someone or something.
- To publicly acknowledge or thank someone.
A2Moretag
US /tæɡ/
UK /tæɡ/
- Noun (Countable/Uncountable)
- Child's game in which one person chases the others
- A name or label on something or someone
- Transitive Verb
- To apply a name or label to something or someone
- To touch someone you are chasing in a game
B1Moretag on
US /tæg ɑn/
UK /tæg ɒn/
- other
- To add something extra or join a group or activity.
B2Moretalking about
US
UK
- Phrasal Verb
- To discuss a particular topic.
- To be constantly mentioning or bringing up a subject.
A1Morethink about
US /θɪŋk əˈbaʊt/
UK /θiŋk əˈbaut/
- Phrasal Verb
- To consider something carefully.
- To remember or call to mind.
A1Morethink of
US /θɪŋk ʌv/
UK /θiŋk ɔv/
- Phrasal Verb
- To look on as (being something specific); consider
- To consider or remember something.
- Verb (Transitive/Intransitive)
- To imagine or call something to mind
A1Moreto date
US /tu det/
UK /tu: deit/
- Phrase
- Up to the present time; until now.
- Verb (Transitive/Intransitive)
- To go out on romantic dates with someone.
C2Moreto do with
US
UK
- Phrasal Verb
- To be about something; concern
A1Moreto scale
US
UK
- Phrase
- In proportion; maintaining accurate relative dimensions.
- Verb (Transitive/Intransitive)
- To increase or expand proportionally.
- To climb or ascend.
B2Morewith it
US /wɪð ɪt/
UK /wið it/
- Adjective
- Intelligent, alert, and up-to-date.
- Understanding and knowledgeable about current trends or information.
A1Morework on
US /wɚk ɑn/
UK /wə:k ɔn/
- Phrasal Verb
- To devote effort to improve or develop something
- To try to persuade or influence someone.
A1More
Vocabulary
- instead of: When one thing is replaced by another
- going on: To continue doing something
- have to: Must do
- at a time: Separately; one by one
- depending on: To rely on for support (financial or emotional)
- look at: To use your eyes to focus on something
- over time: Gradually; as time passes.
- got to: To arrive at some place
- in terms of
- just kind of: Used to express a feeling or state in a vague or hesitant way.
- in the way: Obstructing someone or something; hindering progress.
- figure out: To understand the behavior of someone
- regardless of
- set up
- look for: To try to find a thing or person that is lost
- fit into: To be small enough to go inside something.
- tag on: To add something extra or join a group or activity.
- based on: To use something as the foundation or starting point for something else.
- rather than: More exactly; more correctly
- think about: To consider something carefully.
- for instance: As an example.
- by default: Automatically, unless the user specifies otherwise.
- in charge: To be responsible for
- for the most part: Generally; mostly; on the whole.
- shout out: A public expression of greeting or praise.
- to do with: To be about something; concern
- go ahead: To start an activity; start doing, working etc.
- bump up: To increase something, often by a small amount.
- go into detail: To explain or describe something fully and completely.
- into detail: To explain or discuss something thoroughly with many specifics.
- in general: Typically; usually; on the whole.
- out of it: Unconscious or not completely alert; dazed or confused.
- by definition: Inherently; as an essential quality or characteristic.
- look around: To explore a place; search for something.
- a couple hundred: Approximately two hundred.
- as useful: Equally useful; to the same degree of usefulness.
- as well as: Also; in addition to
- work on: To devote effort to improve or develop something
- as time goes by: Over the course of time; as time passes.
- run on: To continue longer than expected, e.g. a meeting
- talking about: To discuss a particular topic.
- lead to: To result in some action
- in on: To be involved in a secret or plan.
- for the heck of it: Doing something without serious reason, just out of curiosity or fun.
- bad idea: An unwise or imprudent course of action.
- to scale: In proportion; maintaining accurate relative dimensions.
- to date: Up to the present time; until now.
- on to: Toward something; forward
- go on: To continue doing something
- end in: To have something as the final result.
- join in
- forget about: To stop thinking about something; to ignore something.
- think of: To look on as (being something specific); consider
- right back: Said when someone says they will return soon, indicating you expect their prompt return.
- play around: To cheat on your partner romantically
- with it: Intelligent, alert, and up-to-date.
- compete in: To take part in a contest or competition.
- in case of: If something happens; in the event of.
- field: Area of study, such as physics or biology
- record: Highest or most extreme level achieved
- application: Software program, e.g. for smart phone
- performance: Act of doing something
- primary: Most important, most basic or essential
- d: Fourth letter of the English alphabet
- product: Item that can be bought
- tag: Child's game in which one person chases the others
- index: Number showing how prices, wages changed over time
- table: Diagram that shows data in rows and columns
- key: Answers to exercises, as at the back of a book
- size: How big or small a thing is
- buffer: Data in computer memory allowing fast access
- server: A computer which distributes files to others
- indistinct: Not clearly defined; not easy to see or hear
Get the full experience in the app
Learn anywhere with detailed sentence and usage analysis
01:03
She took a brave step forward, leaving behind her comfort zone to chase her dreams.
Vocabulary
- brave
adj. Having courage
- comfort zone
phr. A familiar situation where one feels safe
Explanation
a brave step is a noun phrase, where brave is an adjective modifying the noun step, meaning "a courageous step".
forward is an adverb modifying step, meaning "ahead".
The whole phrase serves as the object, answering the "what" of took (verb) — she took a brave step forward.
Get the full experience in the app
Look up words anytime with pronunciation, part of speech, and usage
brave
US/brev/
UK/breɪv/
adj.Brave
v.t.To bravely face
A2 Elementary
Get the full experience in the app
Practice speaking anytime and get instant pronunciation feedback
Try this speaking exercise.
Try practicing with this sentence.
80
0
陳柏霖 posted on 2015/02/13Ever wondered how to make your MySQL databases run lightning-fast? This video dives into practical tips for performance tuning, covering everything from benchmarking to indexing guidelines. You'll pick up essential workplace vocabulary and learn how to optimize your queries like a pro!
Learn this video on the APP!
The VoiceTube App has more in-depth practice for videos!